抽取模型
使用示例
基于自研 memos-extractor-0.6b 模型,从对话中抽取事实与偏好记忆。
MemOS 提供记忆抽取接口,基于自研 memos-extractor-0.6b 小模型,开发者可直接传入对话内容,一键提取事实记忆与偏好记忆。
何时使用记忆抽取模型
记忆抽取接口适用于以下场景:
- 轻量级记忆提取:无需部署完整的 add/message 流程,直接从对话中提取结构化记忆。
- 低延迟高频调用:基于 0.6B 自研小模型,适合对延迟敏感、调用频繁的业务场景。
- 灵活的抽取控制:可按需选择抽取事实记忆、偏好记忆或全部,满足不同业务需求。
工作原理
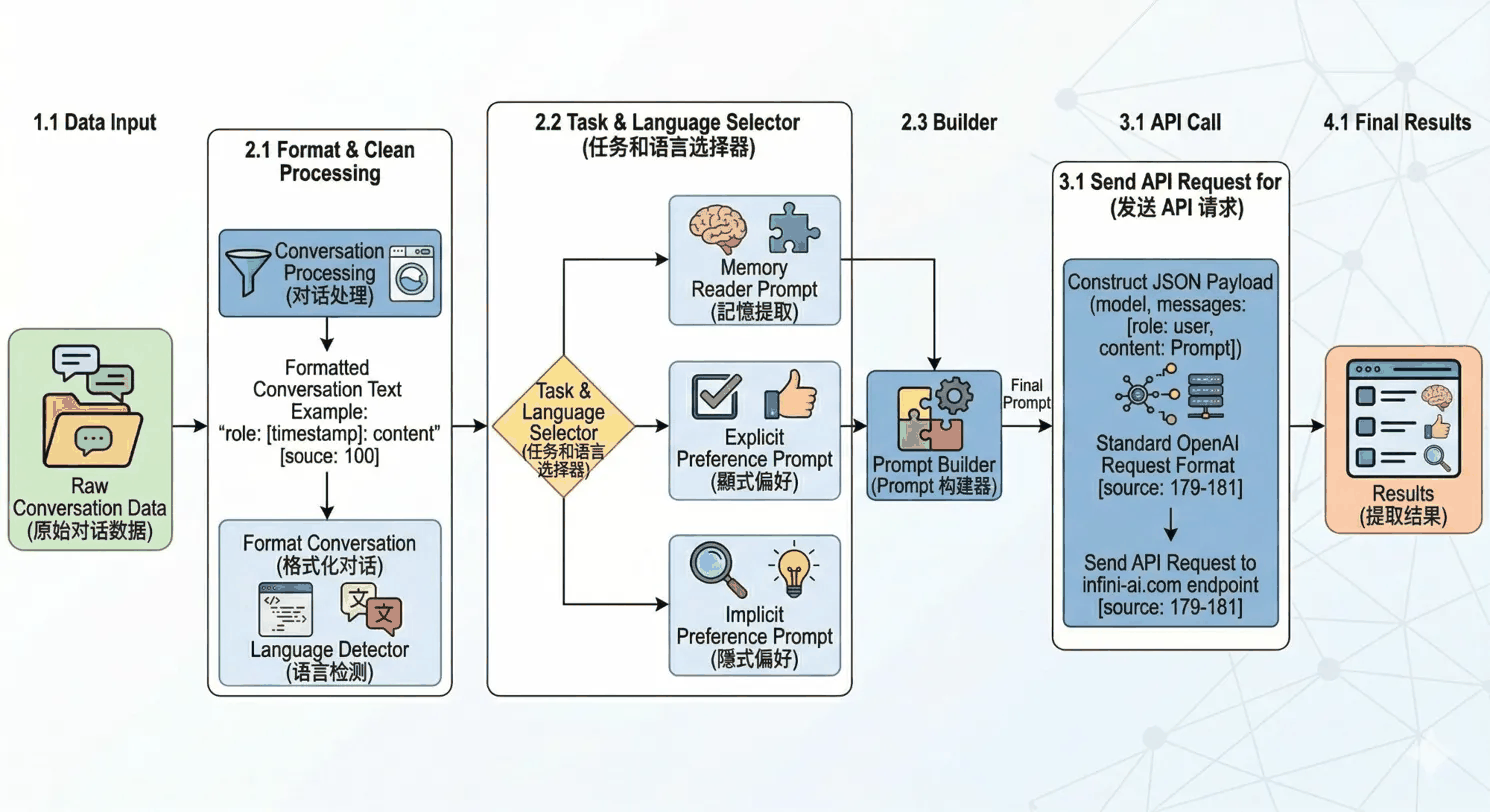
抽取模型的完整调用流程可分为以下步骤:
- 数据输入(Data Input)
开发者传入原始对话数据(messages),每条消息包含role与content字段。 - 格式化与清洗(Format & Clean Processing)
对话内容经格式化处理,统一为标准格式;同时进行语言检测,识别对话所使用的语言。 - 任务与语言选择(Task & Language Selector)
根据extraction_types与检测到的语言,进入对应的抽取分支:- Memory Reader:事实记忆抽取
- Explicit Preference:显性偏好抽取
- Implicit Preference:隐性偏好抽取
- Prompt 构建(Builder)
将当前分支所需的 Prompt 模板组装为最终推理请求。 - API 调用(API Call)
按约定格式请求 memos-extractor-0.6b 模型完成推理。 - 返回结果(Final Results)
模型返回结构化结果,包含事实记忆列表和/或偏好记忆列表(随请求中的抽取类型而定)。
快速上手
import os, json, requests
os.environ["MEMOS_API_KEY"] = "YOUR_API_KEY"
os.environ["MEMOS_BASE_URL"] = "https://memos.memtensor.cn/api/openmem/v1"
data = {
"messages": [
{"role": "system", "content": "从对话中提取关键记忆。"},
{"role": "user", "content": "我叫张三,28岁,杭州后端,喜欢羽毛球。"},
{"role": "assistant", "content": "你好张三!"},
{"role": "user", "content": "回复尽量简洁,别太啰嗦。"},
]
}
headers = {"Content-Type": "application/json", "Authorization": f"Token {os.environ['MEMOS_API_KEY']}"}
url = f"{os.environ['MEMOS_BASE_URL']}/extract/memory"
res = requests.post(url, headers=headers, data=json.dumps(data))
print(res.json())
import os, json, requests
os.environ["MEMOS_API_KEY"] = "YOUR_API_KEY"
os.environ["MEMOS_BASE_URL"] = "https://memos.memtensor.cn/api/openmem/v1"
data = {
"messages": [{"role": "user", "content": "下周三去北京出差,住朝阳全季。"}],
"extraction_types": ["memory"],
}
headers = {"Content-Type": "application/json", "Authorization": f"Token {os.environ['MEMOS_API_KEY']}"}
url = f"{os.environ['MEMOS_BASE_URL']}/extract/memory"
res = requests.post(url, headers=headers, data=json.dumps(data))
print(res.json())
import os, json, requests
os.environ["MEMOS_API_KEY"] = "YOUR_API_KEY"
os.environ["MEMOS_BASE_URL"] = "https://memos.memtensor.cn/api/openmem/v1"
data = {
"messages": [
{"role": "user", "content": "文档用 Markdown,代码块要高亮。"},
{"role": "assistant", "content": "好的。"},
{"role": "user", "content": "少用 emoji。"},
],
"extraction_types": ["preference"],
}
headers = {"Content-Type": "application/json", "Authorization": f"Token {os.environ['MEMOS_API_KEY']}"}
url = f"{os.environ['MEMOS_BASE_URL']}/extract/memory"
res = requests.post(url, headers=headers, data=json.dumps(data))
print(res.json())
输出示意
{
"code": 0,
"message": "ok",
"data": {
"success": true,
"memory_detail_list": [
{
"memory_key": "用户身份与职业",
"memory_value": "用户张三,28岁,在杭州从事后端开发,喜欢打羽毛球。",
"memory_type": "UserMemory",
"tags": ["人物", "职业", "地点", "爱好"]
}
],
"preference_detail_list": [
{
"preference": "希望助理回复尽量简洁,不要过于啰嗦。",
"reasoning": "用户在对话中明确要求「回复尽量简洁一些,不要太啰嗦」。",
"preference_type": "explicit_preference"
}
]
}
}
{
"code": 0,
"message": "ok",
"data": {
"success": true,
"memory_detail_list": [
{
"memory_key": "出差行程与住宿",
"memory_value": "用户下周三将去北京出差,计划入住朝阳区全季酒店。",
"memory_type": "LongTermMemory",
"tags": ["行程", "差旅", "住宿"]
}
]
}
}
{
"code": 0,
"message": "ok",
"data": {
"success": true,
"preference_detail_list": [
{
"preference": "偏好使用带语法高亮的 Markdown 代码块呈现文档内容。",
"reasoning": "用户明确表示喜欢 Markdown 与代码块高亮。",
"preference_type": "explicit_preference"
},
{
"preference": "尽量减少 emoji 的使用。",
"reasoning": "用户直接提出不要用太多 emoji。",
"preference_type": "explicit_preference"
}
]
}
}
使用限制
- 接口输入上限:8,000 tokens。
- 当前仅支持同步模式,接口将在抽取完成后一次性返回结果。
- 当前仅支持传入对话文本:
messages中每条消息仅包含role与content;暂不支持多模态输入,也无法通过本接口抽取多模态记忆。
对比 add/message 接口
| 对比维度 | 记忆抽取接口 | add/message 接口 |
|---|---|---|
| 核心能力 | 从对话中提取记忆,仅返回结果 | 写入对话并自动提取、存储记忆 |
| 记忆存储 | ❌ 不写入 MemOS 记忆库 | ✅ 自动写入 MemOS 记忆库 |
| 推理模型 | 自研 0.6B 小模型,低延迟 | MemOS 内置模型 |
| 异步模式 | 暂不支持 | ✅ 支持 |
| 偏好记忆 | ✅ 支持(显性 + 隐性) | ✅ 支持 |
| 工具记忆 / 技能 | ❌ 不支持 | ✅ 支持 |
| 典型使用场景 | 独立的记忆分析 / 预处理 / 质量评估 | 完整的对话记忆管理 |